TokenKeep — Unlock up to 65% Savings with Predictable AI Costs for Your SaaS
For SaaS founders and CTOs
Your AI Costs Are Out of Control
You launched a great feature. Now you're dealing with:
- Bill Shock: Unexpected charges from bugs or sudden traffic spikes.
- Zero Visibility: No idea which users or features are draining your budget.
- Stalled Growth: You delay launching new features because you fear the cost.
Chaos Stops Growth
Ignoring token waste actively limits your company:
- Eroding Margins: Profit is silently lost to hidden API overages.
- Mismanaged Budgets: You cannot confidently forecast AI expenses for investors or board reports.
- Tech Debt: You're wasting engineering time building custom workarounds instead of product features.
Don’t let chaos take over your business. TokenKeep helps you stay in control.
How TokenKeep Solves This?
TokenKeep sits between your app and the LLM API, ensuring every single token call is optimized, limited, and logged.
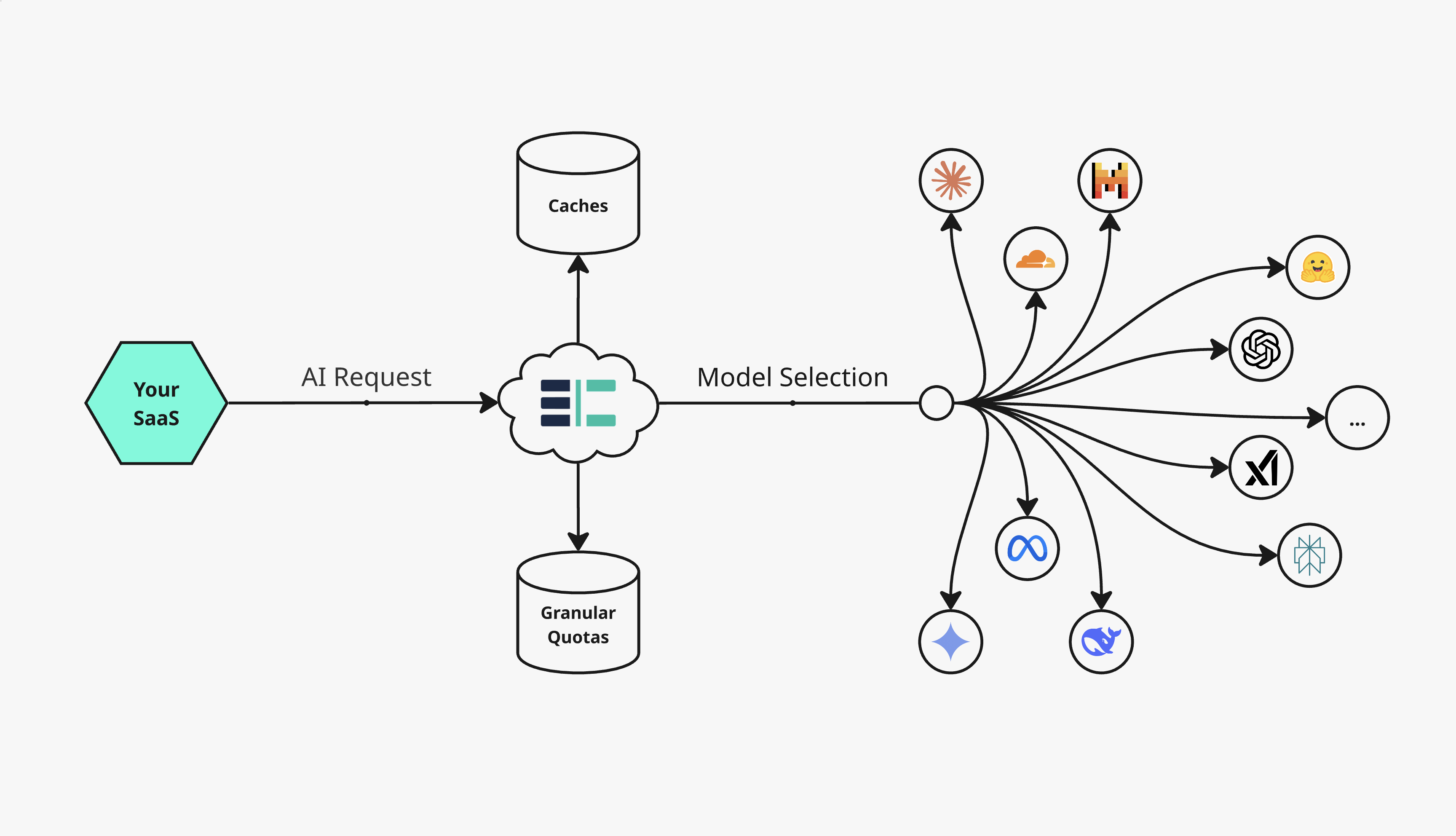
- 1Intercept & Optimize.
- Your requests hit TokenKeep first. We automatically apply caching to reduce the number of paid API calls.
- 2Verify & Limit.
- We check the request against your granular per-user quotas and rate limits. If the limit is hit, the request is blocked, preventing bill shock.
- 3Route & Log.
- The request is sent to the lowest-cost model (or your preferred API). All usage is logged in real-time, giving you 100% visibility.
Everything you need
The One-Stop-Shop for Complete AI Cost Governance
Every tool your SaaS needs to move from token chaos to predictable, profitable AI usage.
- Granular Quotas & Rate Limits
- Set hard, unbreakable budget limits. Define precise spending caps and velocity limits (per user, per feature, per environment). This guarantees zero budget overruns and eliminates the risk of sudden bill shock.
- Usage-Based Billing
- Monetize your AI features accurately. TokenKeep automatically tracks token consumption per end-user and reports it to your existing billing platform (Stripe, Chargebee, Orb, etc.) to implement transparent usage-based pricing models for your customers.
- Request Caching
- Instantly cut redundant token spend. Our cache automatically detects and reuses responses to the same requests. Eliminate unnecessary, repetitive LLM calls to reduce your token bill.
- Smart Model Routing
- Automated best-price execution. Dynamically route requests to the cheapest compatible model based on the task complexity. This guarantees you are never overpaying for simple queries, maximizing margin on every API call.
- Unified API Layer
- Reduce vendor lock-in & dev time. Connect to every major LLM provider (OpenAI, Anthropic, Gemini, etc.) using a single, future-proof endpoint. Your engineers build once, regardless of model changes.
- Real-time Metrics & Analytics
- Full cost transparency. Centralized dashboards provide a clear breakdown of consumption, cost per user, and cost per feature. Identify low-value spending patterns and make data-driven decisions to optimize profitability.
Integrate in Minutes. Save on Every Token.
Swap your existing OpenAI client to the TokenKeep gateway by changing just the API key and base URL.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.TOKENKEEP_API_KEY,
baseURL: "https://api.tokenkeep.ai",
});
Start saving on every token you send.
- bill shocks eliminated through granular quotas and rate limits
- 99.9%
- cost-per-query savings achieved through smart model routing
- up to 65%
- average reduction in LLM costs through intelligent caching
- 30-50%
- average engineering time savings with the unified API layer
- 3-4 Weeks
Ready to Fix Your AI Budget?
Stop being surprised by your AI bills. Get started with predictable spending today.